Zabbix チューニング事例
参考までに弊社のチューニング事例について下記にまとめました。
Apache PHP チューニング
ZabbixのUser Interface(UI)で使用するApache + PHPのチューニング方法についての紹介です。
Zabbixは、User Interfaceにブラウザ(browser)を使用します。Server側は、Httpd + PHP (通常ですとapache + php )を利用しています。
Server側で処理するデータボリュームが増加すると、apache + phpがメモリを異常に消費してPerformanceに影響を与えます。 現象的には、応答速度が遅くなり1つの処理に時間が掛かるようになります。CPUの使用率も急激に増加します。
※PHP自体を解析しているわけではありませんので、PHP自体に問題があるかは不明ですが、検証した結果としてPHPは、異常にメモリを消費しRequestの処理を終了してもメモリを完全に解放していないことから、メモリリークが発生している可能性が非常に高いです。
今回は、この現象を解決(回避)するためのチューニングを紹介します。Apacheをチューニングするには、まずApacheのモジュール (MPM)を知らなければなりません。Apacheのサイトには、モジュール一覧として下記が掲載されています。(下記Apacheに関する説明は、http://www.apache.org/からの抜粋です。)
- beos
This Multi-Processing Module is optimized for BeOS. - event
An experimental variant of the standard worker MPM - mpm_netware
Multi-Processing Module implementing an exclusively threaded web server optimized for Novell NetWare - mpmt_os2
Hybrid multi-process, multi-threaded MPM for OS/2 - prefork
スレッドを使わず、先行して fork を行なうウェブサーバを実装 - mpm_winnt
Windows NT 向けに最適化されたマルチプロセッシングモジュール - worker
マルチスレッドとマルチプロセスのハイブリッド型 ウェブサーバを実装したマルチプロセッシングモジュール
この中でLinuxで利用するのは、preforkとworkerです。それぞれの処理方式の概要としては、下記の説明がされています。
- prefork
このマルチプロセッシングモジュール (MPM) は、 Unix 上での Apache 1.3 のデフォルトの挙動と非常によく似た方法で リクエストを処理する、スレッドを使わず、先行して fork を行なう ウェブサーバを実装しています。スレッドセーフでないライブラリとの互換性をとるために、 スレッドを避ける必要のあるサイトでは、このモジュールの使用が適切でしょう。 あるリクエストで発生した問題が他のリクエストに影響しないように、 個々のリクエストを単離するのにも、最適な MPM です。 - worker
このマルチプロセッシングモジュール (MPM) は、マルチスレッドとマルチプロセスのハイブリッド型サーバを 実装しています。リクエストの応答にスレッドを使うと、プロセスベースのサーバよりも少ないシステム資源で、 多くのリクエストに応答することができます。さらに、多くのスレッドを持った複数のプロセスを維持することで、プロセスベースのサーバの持つ安定性を保持しています。
今回問題として顕在化しているのは、apache + phpがメモリ,CPUを以上に消費してPerformanceに影響を与えている部分です。
本来であればphp自体の問題と推測できるのですが、apacheの追加モジュールとして読ませています。apacheのプロセス自体を解放する事によりphpのメモリも解放するのが適切ですので、workerよりもpreforkのMPMを選択するほうが適切ということになります。
preforkの設定はversionによって異なると思いますが下記をご参考ください。
<IfModule prefork.c>
StartServers 8
MinSpareServers 5
MaxSpareServers 20
ServerLimit 256
MaxClients 256
MaxRequestsPerChild 4000
</IfModule>
StartServers 8
MinSpareServers 5
MaxSpareServers 20
ServerLimit 256
MaxClients 256
MaxRequestsPerChild 4000
</IfModule>
其々の設定値の説明は下記になります。
- StartServers
起動時に生成される子サーバプロセスの数
StartServers ディレクティブは、 起動時に生成される子サーバプロセスの数を設定します。 - MinSpareServers
アイドルな子サーバプロセスの最小個数
MinSpareServers ディレクティブは、 アイドルな子サーバプロセスの希望最小個数を設定します。 アイドルプロセスとは、リクエストを扱っていないプロセスです。 MinSpareServers よりも少ない数がアイドルであれば、 親プロセスは最高で 1 秒につき 1 個の割合で新しい子プロセスを生成します。 - MaxSpareServers
アイドルな子サーバプロセスの最大個数
MaxSpareServers ディレクティブは、アイドルな子サーバプロセスの希望最大個数を設定します。 MaxSpareServers よりも多い数がアイドルであれば、親プロセスは超過プロセスをkill します。 - ServerLimit
設定可能なサーバプロセス数の上限
prefork MPM の場合は、このディレクティブは Apache プロセス稼働中におけるMaxClients に設定可能な上限値を設定することになります。 (訳注: prefork の場合は、同時クライアント数 = サーバプロセス数なので) 。 - MaxClients
リクエストに応答するために作成される子プロセスの最大個数
MaxClients ディレクティブは、 応答することのできる同時リクエスト数を設定します。 MaxClients 制限数を越えるコネクションは通常、 ListenBacklogディレクティブで設定した数までキューに入ります。 他のリクエストの最後まで達して子プロセスが空くと、次のコネクションに応答します。 - MaxRequestsPerChild
個々の子サーバが稼働中に扱うリクエスト数の上限
MaxRequestsPerChild ディレクティブは、 個々の子サーバプロセスが扱うことのできるリクエストの制限数を 設定します。 MaxRequestsPerChild 個数のリクエストの後に、子プロセスは終了します。 MaxRequestsPerChild が 0 に設定されている場合は、プロセスは期限切れにより終了することはありません。
マニュアルの説明ですと少々わかりにくいのですが、apacheのプロセス自体を解放する事によりphpのメモリも解放するには、apacheのclientプロセスを再起動する必要があります。ここで注目する設定値は、MaxRequestsPerChildになります。
MaxRequestsPerChildを超えると自動的に処理プロセスが終了し、全メモリを解放することになります。
実際にZabbixの動作に合わせた設定チューニングとしては、下記のような感じになります。
<IfModule prefork.c>
StartServers 3
MinSpareServers 2
MaxSpareServers 3
ServerLimit 30
MaxClients 30
MaxRequestsPerChild 50
</IfModule>
StartServers 3
MinSpareServers 2
MaxSpareServers 3
ServerLimit 30
MaxClients 30
MaxRequestsPerChild 50
</IfModule>
- StartServers
Zabbixでは大して意味が無いので少ない数値にします。 - MinSpareServers
これは、瞬間風速のリクエストのための予備能力になります。
つまり、瞬間的に同時に開くブラウザの数(ページ)に依存します。
Zabbixでは、Webページの表示処理とは別にHttpRequestを使用して並行してデータを取得する部分がありますので、同時に開くブラウザの数(ページ)×2を設定する事になりますが、GUIを同時に開くことは稀ですし、Request自体はキューに溜められるので、ここでは、2を設定しています。 - MaxSpareServers
MinSpareServersと同様の目的ですので、MinSpareServers+1で3にしています。 - ServerLimit
これは、同時に処理しているページ数の最大を設定しますが、同時に処理をする事を予測するのは難しいので開いているトータルのページ数×2で+αを設定します。
特にグラフ表示などをする場合は、処理に時間がかかりますのでαを少し大きめにします。 - MaxClients
ServerLimitと同じ数値で、特に問題はおきません。 - MaxRequestsPerChild
一番重要なパラメータなのですが、各ページでRequest数が異なりますので、絶対値は無いのですが、20-50程度が妥当な値です。
以上で、設定値のチューニングの説明は終了です。
Windows 2008 Performance Counter
Zabbixは、windowsのperformce counterのデータもItemとして収集可能です。performce counterをItem keyとして登録する場合、直接対象カウンターを入力する必要がありますが、1文字でも間違うと当然のごとくデータが収集できません。
※"*"は、もともと収集できません。
そこで、簡単とは言いませんが、コピー&ペーストで、カウンターをItem Keyとして利用できる方法を紹介します。
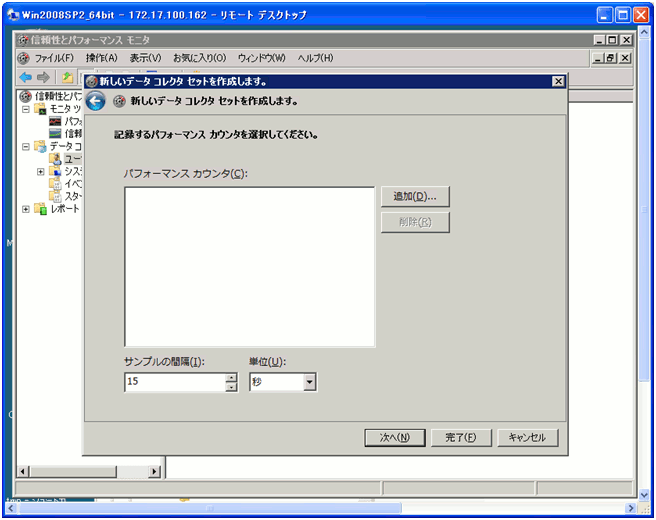
- 管理者ツールから、パフォーマンスモニターを起動します。
- ユーザ定義を選択して、新規にデータコレクトセット作成を選びます。
- 手動で作成するを選択して、次の画面へ移動します。
- パフォーマンスカウンターを選択して、次の画面へ移動します。
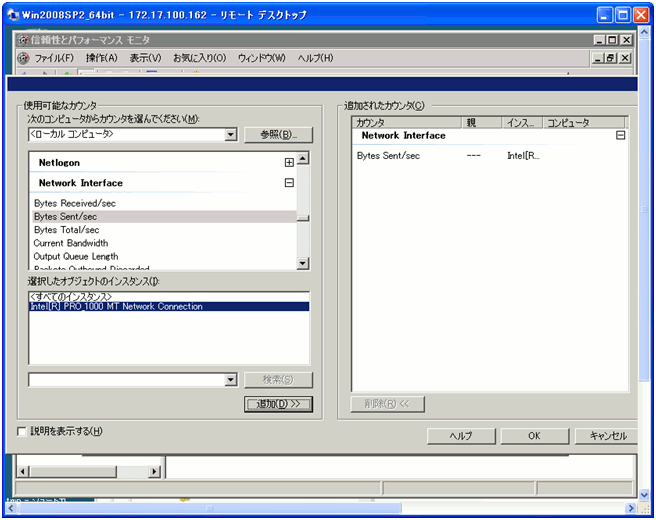
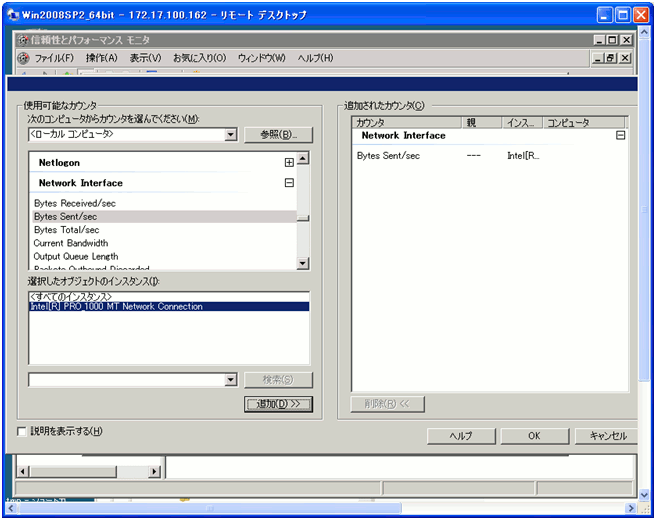
- 追加を選択します。
- ローカルコンピュータで、取得可能なカウンターの一覧が表示されますので、取得する対象を選択します。
- 追加を押下するとカウンターが登録されますので、OKを選択します。
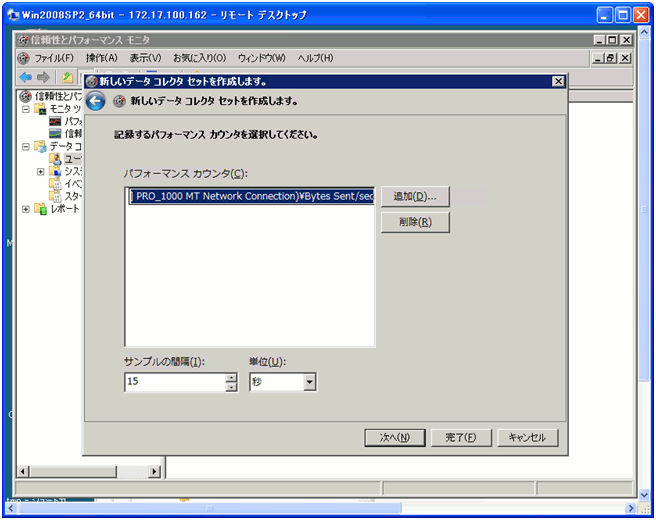
- 画面上、カウンターが登録されてますので、クリックしてください。
コピー&ペーストできる状態になりますので、クリップボードへコピーして、ZabbixのItem keyへペーストします。 - 最後に、必要のなくなった、データコレクタセットをユーザ定義から削除します。
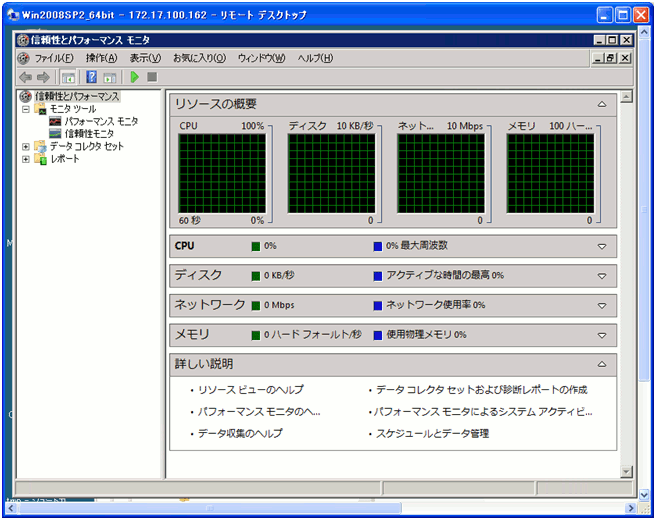
クリックで拡大
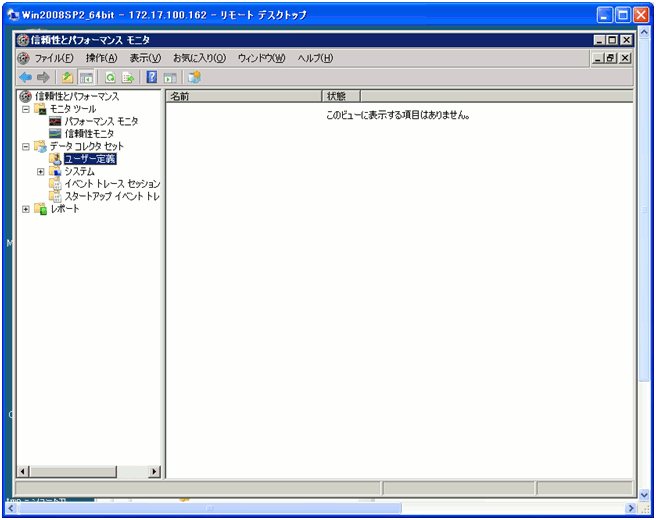
クリックで拡大
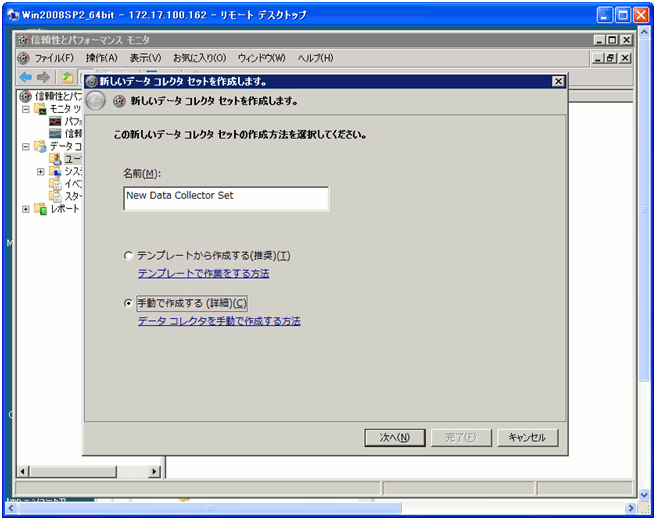
クリックで拡大
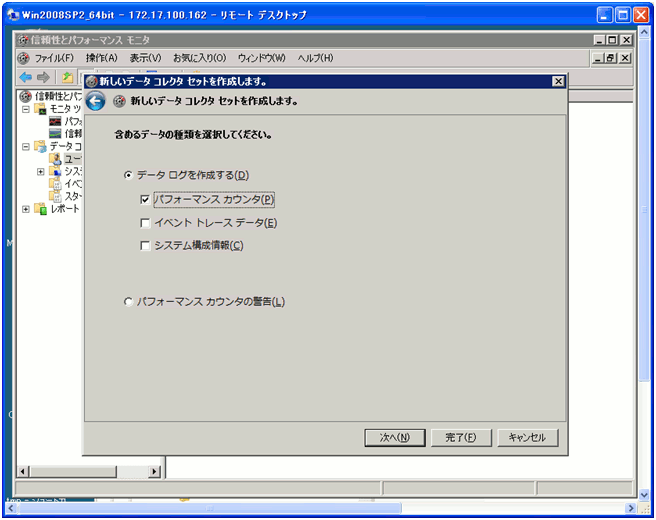
クリックで拡大
クリックで拡大
クリックで拡大
クリックで拡大
クリックで拡大
ZabbixとMySQL Partitioning(Zabbix 2.0の検証事例)
Partitioningの必要性
Zabbixでは、収集したデータをDatabaseに保存して、後で再利用できる構成となっています。保存期間もユーザ側で指定する事ができますので、保存できるデータは、Databaseの能力次第という事になります。
しかし、全ての生データは、history関連テーブルに格納されますので、格納データが多くなる事によりDatabaseの処理が重くなりシステム全体のパフォーマンスは低下します。また、Triggerで検知したイベントもeventsテーブルに格納されますので、こちらもデータが多くなる事によりシステムのパフォーマンスは低下します。
Zabbixは、非常に軽量で、高速に動作するように作られており、格納対象データもWrite Cacheに保管しておきBulk Insert,Updateをする事により処理負荷の軽減を図っています。 しかし、Timer系のTrigger、Housekeeper処理、Web画面、グラフ関係表示は、Bulk処理が出来ないため、DatabaseのCache設定に依存します。
Databaseは、Indexが適用されていても検索母体件数が多くなる事により一気に性能が落ちます。
例えば、1600 Itemのデータを5秒間隔で取得すると下記のようになります。
- 1時間で、1600 × 3600 ÷ 5 = 1,152,000
- 1日で、1,152,000 × 24 = 27,648,000
- 1週間で、27,648,000 × 7 = 193,536,000
この件数では、いくらIndexが適用されていてもCPU,I/Oの負荷、レスポンスは悪くなります。
そこで、DatabaseのPartitioning機能を適用して、どの程度効果が得られるのか?について、検証を行いました。
MySQL:Partitioning方式
MySQLのPartitioningには、下記の4種類が提供されています。
| Partitioning | 概要 |
|---|---|
| RANGE | パーティション毎に範囲(RANGE)で、対象パーティションを指定 |
| LIST | パーティション毎に格納する値をListで対象パーティションを指定 |
| HASH | 1つのカラムの値を式の結果で対象パーティションを指定(デフォルトは、MOD)大量のデータにはLINEAR HASHが用意されている |
| KEY | 1つ以上のカラムの値をMD5関数やPassword関数で評価して対象パーティションを指定 |
| Composite | 上記Range,Listで、各パーティションに分割したものを更に、HASH または KEYで、サブパーティションに分割 |
どのPartitioningを使用するかは、Zabbixからのアクセス方法によって決定します。
適切に分割すれば、操作対象母体データ件数が少なくなりますのでシステム負荷が軽くなりレスポンスも速くなります。
下記にデータ量が多くなりやすいTableおよび主なアクセス方法を示します。
大規模環境になると下記の他にもItems,Trigger,etcとPartition化の対象となるTableが増えますが、基本的な考え方は同じで、データ量に応じて、適切なPartition化の検討が必要になります。
| Table | 概要 | 主なアクセス方法 |
|---|---|---|
| history* | 収集した生データを格納するテーブル。 | itemid + clockにてアクセス |
| trends* | history*のSummaryを格納するテーブル。 | itemid + clockにてアクセス |
| events | トリガーで検知したイベントを格納するテーブル | clockにてアクセス |
| audit | Security情報、変更情報を格納するテーブル | clockにてアクセス |
それぞれのテーブルに対して、どのPartition構成が適切なのかですが、 History* , trends*テーブルは、Partition化のKeyとして、ItemID または、Clockを利用できます。
- ItemIDを利用する場合は、Hash Partition
- Clockを利用する場合は、Range Partition
- ClockとItemIDの両方を利用する場合は、Composite Partition
でPartition化する事になります。
Events,auditテーブルは、Clockでのアクセスになりますので、Range Partitionを利用する事になります。Hash PartitionとRange Partitionの其々の利点ですが、ItemIDで、Hash Partitionは、なんといっても管理が楽です。分割数の増減も容易ですし空Partitionのチェックも必要ありません。
ClockでRange Partitionを利用する場合のメリットは、古いデータ(Partition)にアクセスしないようにできる点です。直近のデータのみ専用Partitionに格納する事により、高速なレスポンスを維持する事が出来ます。ただし、Partitionの分割、管理をメンテナンスとして定期的に実施する必要があります。
Composite Partitionを利用する場合のメリットは、Range Partitionのメリットと同様にデータ(Partition)にアクセスしないようにできる点があります。Compositeでは、更にItemIDをPartition keyとしてHashでSub Partitionを構成しますので、データ収集間隔が短く、かつ収集対象Item数が多いときでも、高速なレスポンスを維持する事が出来ます。ただし、Range Partitionと同様にPartitionの分割、管理をメンテナンスとして定期的に実施する必要があります。
Range Partition設計する際の追加注意事項
history関係テーブルは、Webからの参照の最小値が1時間ですので、データ量が多くても1時間以内を分割しても意味がありません。検証していませんが、恐らくOverheadが大きくなり、逆に遅くなります。トリガー等の設定にもよりますが、Zabbix Serverは、最新データを利用しますので、最新データを含むPartitionは、小さい方が良い事になります。
1日以上経過したデータは、Historyとして利用するケースが非常に少なくなりますので、Partition分割によるOverheadを少なくするために統合した方が良いケースがあります。 保存期間を経過したデータは、自動的に削除されますので、空のPartitionは、Dropするべきです。
trends関係テーブルは、history関係テーブルのSummaryになりますので、日単位、月単位で分割すると、その時のデータ量によってバラツキが発生し分割によるOverheadを考慮する必要があります。保存期間を経過したデータは、自動的に削除されますので、空のPartitionは、Dropするべきです。
Events,Audit関係テーブルは、イベントの発生または、構成の変更等によりデータが作成されますので、日単位、月単位で分割すると、その時のデータ量によってバラツキが発生し分割によるOverheadの方が大きくなります。したがって、件数に合わせて分割するべきでしょう。
Partitioning : 検証環境と負荷設定
検証環境
| - | MySQL | MySQL-Partitioning |
|---|---|---|
| OS | Redhat 6.2 | Redhat 6.2 |
| Memory | 1GB | 1GB |
| vCPU | 1 | 1 |
| Zabbix | 2.0.0 | 2.0.0 |
| Apache | 2.2.15 | 2.2.15 |
| Php | 5.3.3 | 5.3.3 |
| MySQL | 5.5.24 | 5.5.24 |
MySQL設定
標準で用意されているmy-medium.cnfを使用しています。また、下記パラメータを追加で設定しています。
- innodb_file_per_table
- innodb_log_file_size = 50M
- character-set-server=utf8
- skip-character-set-client-handshake
Zabbix設定
IPアドレス等の設定のみ変更しています。
測定環境
| - | MySQL |
|---|---|
| OS | Redhat 6.2 |
| Memory | 1GB |
| vCPU | 1 |
| Zabbix | 2.0.0 |
| Apache | 2.2.15 |
| Php | 5.3.3 |
| MySQL | 5.5.24 |
負荷設定
今回の測定では、Write処理の多くは、Zabbix Serverですが、Read処理は、Webからの参照の割合が多くなるように負荷設定をしています。特にグラフ表示では、多くのデータを読み込んで負荷が掛かるようにしています。
※幾つかのITEMが収集エラーになりましたが、数が少ないので無視しています。
| 項目 | 設定・値 |
|---|---|
| ホスト数 | 14(redhat) |
| 総Item数 | 1512(Zabbix Agentを利用するITEMのみ) 収集間隔 5秒 ヒストリー保持期間 90日 トレンド保持期間 365日 |
| 総トリガー数 | 528 |
| Web画面 | Dashboard トリガー一覧 すべて表示 イベント一覧 すべて表示 グラフ(6枚) 1グラフに1日分の10Itemを同時表示 グラフ(4枚) 1グラフに1日分の2Itemを同時表示 リフレッシュ間隔30秒 |
テーブルのPartitioning化
本検証で実施したPartition化の方法について説明します。なお、既にZabbix用のDatabaseが構築されている状態からPartition構成に変更する事を前提としています。MySQLでは、PartitioningのKeyとして利用する場合、少し制約がありますので、今回対象とするテーブルPrimary Keyを少し変更する必要があります。
利用されているVersionによって多少違いがあると思いますので、詳細は、MySQLのマニュアルを参照してください。
※Partition化検証のために、Primary key , Indexの変更を行っています。
Sourceを確認して動作上問題ないと判断しておりますが、Originalの制御と異なりますので利用される場合は、十分注意してください。
Range Partition
Range Partitioningでは、PartitionのKeyにClockを利用するために、デフォルトのPrimary Keyを変更するものです。
- history,trends関係テーブルのItemidとclockをPrimary keyとする
Partition KeyにClockを指定して、Range Partitionを設定
パーティションの分割は、メンテナンス用のProcedureにて実施 - events,Audit関係テーブルのeventid, clockおよびauditid, clockをPrimary keyとする
Partition KeyにClockを指定して、Range Partitionを設定
パーティションの分割は、メンテナンス用のProcedureにて実施
実際に使用したSQL
Drop Index history_1 on history;
ALTER TABLE history ADD PRIMARY KEY (itemid,clock);
ALTER TABLE history PARTITION BY RANGE( clock ) ( PARTITION pmax VALUES LESS THAN (MAXVALUE));
Drop Index history_uint_1 on history_uint;
ALTER TABLE history_uint ADD PRIMARY KEY (itemid,clock);
ALTER TABLE history_uint PARTITION BY RANGE( clock ) ( PARTITION pmax VALUES LESS THAN (MAXVALUE));
Drop Index history_log_2 on history_log;
ALTER TABLE history_log DROP PRIMARY KEY, ADD PRIMARY KEY (itemid,id,clock);
ALTER TABLE history_log PARTITION BY RANGE( clock ) ( PARTITION pmax VALUES LESS THAN (MAXVALUE));
Drop Index history_text_2 on history_text;
ALTER TABLE history_text DROP PRIMARY KEY, ADD PRIMARY KEY (itemid,id,clock);
ALTER TABLE history_text PARTITION BY RANGE( clock ) ( PARTITION pmax VALUES LESS THAN (MAXVALUE));
ALTER TABLE trends PARTITION BY RANGE( clock ) ( PARTITION pmax VALUES LESS THAN (MAXVALUE));
ALTER TABLE trends_uint PARTITION BY RANGE( clock ) ( PARTITION pmax VALUES LESS THAN (MAXVALUE));
Maintenance Procedure : Zabbix 2.0.0 for Range Partition
下記は、今回利用したpartitionのメンテナンス用のProcedureです。
DROP PROCEDURE maintenance_table_range;
DELIMITER //
CREATE PROCEDURE zabbix.maintenance_table_range (TABLENAME varchar(64))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE TNAME varchar(128);
DECLARE PNAME varchar(128);
DECLARE TROWS INT;
DECLARE NEXTCLOCK timestamp;
DECLARE CLOCK int;
DECLARE PARTITIONNAME varchar(128);
DECLARE flag INT DEFAULT 0;
DECLARE pmax_rows INT DEFAULT 0;
DECLARE cur1 CURSOR FOR SELECT TABLE_NAME,PARTITION_NAME,TABLE_ROWS FROM information_schema.partitions;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
SET NEXTCLOCK = DATE_ADD(NOW(),INTERVAL -6 HOUR);
SET PARTITIONNAME = DATE_FORMAT( NEXTCLOCK, 'p%Y%m%d_%H' );
OPEN cur1;
REPEAT
FETCH cur1 INTO TNAME,PNAME, TROWS;
IF NOT done THEN
IF TNAME = TABLENAME and PNAME <> PARTITIONNAME and PNAME <> 'pmax' and TROWS = 0 THEN
SET @sql = CONCAT( 'ALTER TABLE ', TABLENAME, ' DROP PARTITION ', PNAME , ';' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
IF TNAME = TABLENAME and PNAME = PARTITIONNAME THEN
SET flag = 1;
END IF;
IF TNAME = TABLENAME and PNAME = 'pmax' THEN
SET pmax_rows = TROWS;
END IF;
END IF;
UNTIL done END REPEAT;
CLOSE cur1;
IF flag = 0 and pmax_rows > 5000000 THEN
SET CLOCK = UNIX_TIMESTAMP(DATE_FORMAT(NEXTCLOCK,'%Y-%m-%d %H:00:00'));
SET @sql = CONCAT( 'ALTER TABLE ',
TABLENAME,
' REORGANIZE PARTITION pmax INTO ',
'(PARTITION ',PARTITIONNAME,' VALUES LESS THAN (',CLOCK,'),',
' PARTITION pmax VALUES LESS THAN (MAXVALUE));');
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END //
DELIMITER ;
DROP PROCEDURE maintenance;
DELIMITER //
CREATE PROCEDURE zabbix.maintenance()
BEGIN
CALL zabbix.maintenance_table_range("history");
CALL zabbix.maintenance_table_range("history_uint");
CALL zabbix.maintenance_table_range("history_log");
CALL zabbix.maintenance_table_range("history_text");
CALL zabbix.maintenance_table_range("trends");
CALL zabbix.maintenance_table_range("trends_uint");
END //
DELIMITER ;
Hash Partition
Hash Partitioningでは、PartitionのKeyにClockを利用するために、デフォルトのPrimary Keyを変更するものです。
- history,trends関係テーブルのItemidとclockをPrimary keyとする
Partition Keyにitemidを指定して、Hash Partitionを設定
パーティションの分割は、メンテナンス用のProcedureにて実施 - events,Audit関係テーブルはZabbix 2.0.0では、参照整合性制約(Foreign key)が設定されています
MySQLでは、PartitionテーブルのForeign keyは、サポートされていませんので、今回はPartition化の対象から外します。
実際に使用したSQL
alter table history add primary key ( itemid,clock,ns);
drop index history_1 on history;
alter table history PARTITION BY LINEAR hash(itemid) PARTITIONS 16;
alter table history_uint add primary key ( itemid,clock,ns);
drop index history_uint_1 on history_uint;
alter table history_uint PARTITION BY LINEAR hash(itemid) PARTITIONS 16;
alter table history_log drop primary key , add primary key (itemid,clock,ns);
ALTER TABLE history_log PARTITION BY LINEAR hash(itemid) PARTITIONS 16;
drop index history_log_1 on history_log;
alter table history_text drop primary key;
alter table history_text add PRIMARY KEY (itemid,clock,ns);
ALTER TABLE history_text PARTITION BY LINEAR hash(itemid) PARTITIONS 16;
drop index history_text_1 on history_text;
alter table trends PARTITION BY LINEAR hash(itemid) PARTITIONS 16;
alter table trends_uint PARTITION BY LINEAR hash(itemid) PARTITIONS 16;
Composite Partition
Composite Partitioningでは、PartitionのKeyにClockを利用するために、デフォルトのPrimary Keyを変更するものです。
- history,trends関係テーブルのItemidとclockをPrimary keyとする
Partition KeyにClockを指定して、Range Partitionを設定
Sub Partition Keyにitemidを指定して、Hash Partitionを設定
パーティションの分割は、メンテナンス用のProcedureにて実施 - events,Audit関係テーブルはZabbix 2.0.0では、参照整合性制約(Foreign key)が設定されています
MySQLでは、PartitionテーブルのForeign keyは、サポートされていませんので、今回はPartition化の対象から外します。
実際に使用したSQL
Drop Index history_1 on history;
ALTER TABLE history ADD PRIMARY KEY (itemid,clock);
ALTER TABLE history PARTITION BY RANGE( clock )
SUBPARTITION BY HASH( itemid ) SUBPARTITIONS 8
( PARTITION pmax VALUES LESS THAN (MAXVALUE));
Drop Index history_uint_1 on history_uint;
ALTER TABLE history_uint ADD PRIMARY KEY (itemid,clock);
ALTER TABLE history_uint PARTITION BY RANGE( clock )
SUBPARTITION BY HASH( itemid ) SUBPARTITIONS 8
( PARTITION pmax VALUES LESS THAN (MAXVALUE));
Drop Index history_log_2 on history_log;
ALTER TABLE history_log DROP PRIMARY KEY, ADD PRIMARY KEY (itemid,id,clock);
ALTER TABLE history_log PARTITION BY RANGE( clock )
SUBPARTITION BY HASH( itemid ) SUBPARTITIONS 8
( PARTITION pmax VALUES LESS THAN (MAXVALUE));
Drop Index history_text_2 on history_text;
ALTER TABLE history_text DROP PRIMARY KEY, ADD PRIMARY KEY (itemid,id,clock);
ALTER TABLE history_text PARTITION BY RANGE( clock )
SUBPARTITION BY HASH( itemid ) SUBPARTITIONS 8
( PARTITION pmax VALUES LESS THAN (MAXVALUE));
ALTER TABLE trends PARTITION BY RANGE( clock ) ( PARTITION pmax VALUES LESS THAN (MAXVALUE));
ALTER TABLE trends_uint PARTITION BY RANGE( clock ) ( PARTITION pmax VALUES LESS THAN (MAXVALUE));
Maintenance Procedure of Zabbix 2.0.0 for composite partition
下記は、今回利用したpartitionのメンテナンス用のProcedureです。
DROP PROCEDURE maintenance_table_range;
DELIMITER //
CREATE PROCEDURE zabbix.maintenance_table_range (TABLENAME varchar(64))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE TNAME varchar(128);
DECLARE PNAME varchar(128);
DECLARE TROWS INT;
DECLARE NEXTCLOCK timestamp;
DECLARE CLOCK int;
DECLARE PARTITIONNAME varchar(128);
DECLARE flag INT DEFAULT 0;
DECLARE pmax_rows INT DEFAULT 0;
DECLARE cur1 CURSOR FOR SELECT TABLE_NAME,PARTITION_NAME,max(TABLE_ROWS) as TABLE_ROWS FROM information_schema.partitions group by TABLE_NAME,PARTITION_NAME;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
SET NEXTCLOCK = DATE_ADD(NOW(),INTERVAL -6 HOUR);
SET PARTITIONNAME = DATE_FORMAT( NEXTCLOCK, 'p%Y%m%d_%H' );
OPEN cur1;
REPEAT
FETCH cur1 INTO TNAME,PNAME, TROWS;
IF NOT done THEN
IF TNAME = TABLENAME and PNAME <> PARTITIONNAME and PNAME <> 'pmax' and TROWS = 0 THEN
SET @sql = CONCAT( 'ALTER TABLE ', TABLENAME, ' DROP PARTITION ', PNAME , ';' );
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
IF TNAME = TABLENAME and PNAME = PARTITIONNAME THEN
SET flag = 1;
END IF;
IF TNAME = TABLENAME and PNAME = 'pmax' THEN
SET pmax_rows = TROWS;
END IF;
END IF;
UNTIL done END REPEAT;
CLOSE cur1;
IF flag = 0 and pmax_rows > 5000000 THEN
SET CLOCK = UNIX_TIMESTAMP(DATE_FORMAT(NEXTCLOCK,'%Y-%m-%d %H:00:00'));
SET @sql = CONCAT( 'ALTER TABLE ',
TABLENAME,
' REORGANIZE PARTITION pmax INTO ',
'(PARTITION ',PARTITIONNAME,' VALUES LESS THAN (',CLOCK,'),',
' PARTITION pmax VALUES LESS THAN (MAXVALUE));');
PREPARE STMT FROM @sql;
EXECUTE STMT;
DEALLOCATE PREPARE STMT;
END IF;
END //
DELIMITER ;
DROP PROCEDURE maintenance;
DELIMITER //
CREATE PROCEDURE zabbix.maintenance()
BEGIN
CALL zabbix.maintenance_table_range("history");
CALL zabbix.maintenance_table_range("history_uint");
CALL zabbix.maintenance_table_range("history_log");
CALL zabbix.maintenance_table_range("history_text");
CALL zabbix.maintenance_table_range("trends");
CALL zabbix.maintenance_table_range("trends_uint");
END //
DELIMITER ;
Range Partition検証
グラフの表示項目ですが、MySQL(Non Partition)は、Partition構成ではないOriginalのデータベース構成です。MySQL_PTN(Partitioned)は、Originalのデータベース構成をclockをPartition KeyにしてPartition化した構成です。
history関連テーブルの件数推移
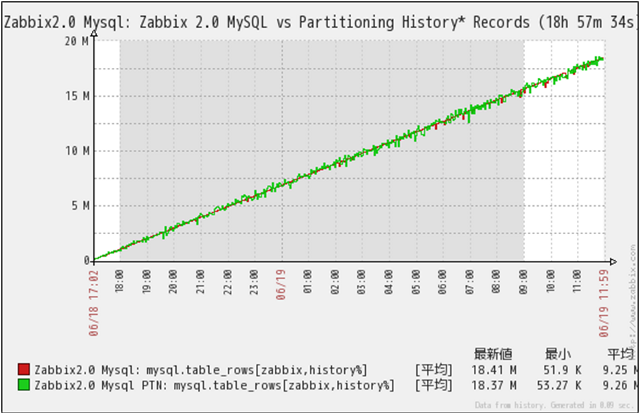
クリックで拡大
一番データ量が増える生データの格納先history関連テーブルの件数推移です。
MySQL(Non Partition)、MySQL_PTN(Partitioned)共に格納データが直線的に増加しており、格納件数の伸びが落ち込んでいない事が判ります。データ件数は、information_schema.TABLESから取得しています。この時点では、Insert処理のみで、Delete処理は、実行されていないはずなのですが、カウントされているレコード件数が増減する現象が出ています。
CPU Idleの推移
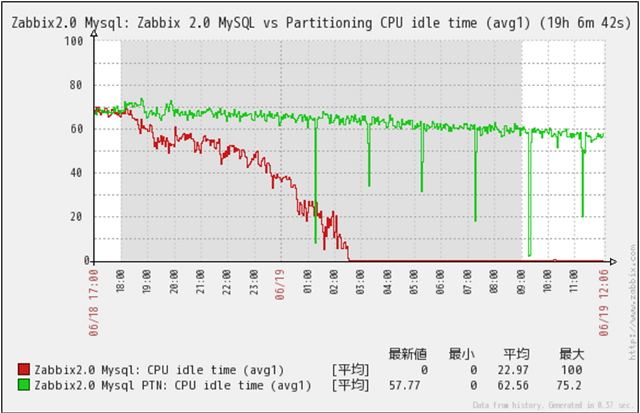
クリックで拡大
CPU Idleの推移です。
MySQL(Non Partition)の場合、格納データ件数増加に伴いCPU Idleが大きく減少している事が判ります。
MySQL_PTN(Partitioned)の場合、格納データ件数増加に伴いCPU Idleが減少しているのですが、MySQL(Non Partition)程の大きな減少は、発生しておらずデータ件数が1千万件を超えても大きな問題が発生していない事が判ります。時々、CPU Idleが急減する現象がありますが、これは、Partitionを分割するAlter Table文を発行した時に発生したものです。
測定初期に、CPU Idleの急減が見られないのは、レコード件数自体が少ないためと推測できます。
Disk Read回数
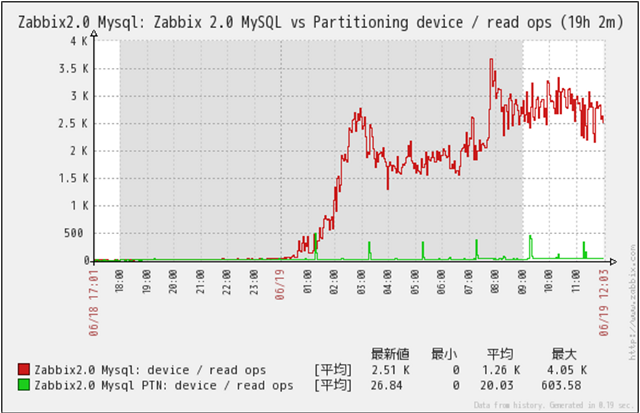
クリックで拡大
Disk Read回数の推移です。
MySQL(Non Partition)の場合、データ量増加に伴い限界を超えた所から、Read回数が急激に多くなっている事が判ります。
母体データ量が多くなり、メモリで処理できる限界値を超えた事によりDisk Readが多くなったものと推測できます。
MySQL_PTN(Partitioned)の場合、格納データ件数増加に伴うRead回数の上昇はほとんど見られません。
アクセス対象の母体データ量がPartition化により抑えられた事により、メモリ内で処理できているため、Read回数の急激な上昇が発生しなかったと推測できます。
Disk Write回数
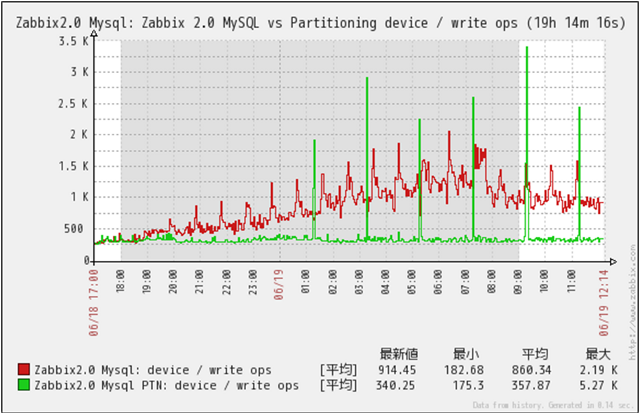
クリックで拡大
Disk Write回数の推移です。
MySQL(Non Partition)の場合、history関連テーブルのデータ量増加に伴いWrite回数が徐々に増えている事が判ります。
一定時間での収集するデータ量自体は増加していませんので、データ量増加によりSort等の処理がメモリ内で処理できる限界を超えた事によりI/Oが発生したものと推測できます。
MySQL_PTN(Partitioned)の場合は、一定のWrite回数で安定して動作している事が判ります。
今回は、収集データ量およびWebからのアクセスによる負荷をかけていますので、Read回数ほどの差は、出ていません。
Hash Partition検証
グラフの表示項目ですが、MySQL(Non Partition)は、Partition構成ではないOriginalのデータベース構成です。MySQL_PTN(Partitioned)は、Originalのデータベース構成をitemidをPartition KeyにしてPartition化した構成です。
history関連テーブルの件数推移
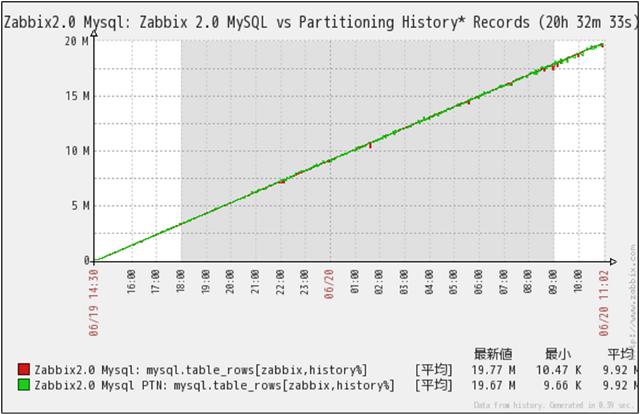
クリックで拡大
一番データ量が増える生データの格納先history関連テーブルの件数推移です。
MySQL(Non Partition)、MySQL_PTN(Partitioned)共に格納データが直線的に増加しており、格納件数の伸びが落ち込んでいない事が判ります。
データ件数は、information_schema.TABLESから取得しています。この時点では、Insert処理のみで、Delete処理は、実行されていないはずなのですが、カウントされているレコード件数が増減する現象が出ています。
CPU Idleの推移
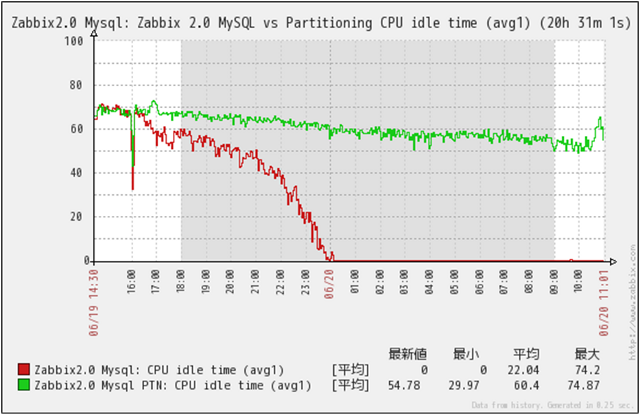
クリックで拡大
CPU Idleの推移です。
MySQL(Non Partition)の場合、格納データ件数増加に伴いCPU Idleが大きく減少している事が判ります。
MySQL_PTN(Partitioned)の場合、格納データ件数増加に伴いCPU Idleが減少しているのですが、MySQL(Non Partition)程の大きな減少は、発生しておらずデータ件数が1千万件を超えても大きな問題が発生していない事が判ります。測定初期に、CPU Idleの急減が見られないのは、レコード件数自体が少ないためと推測できます。
Disk Read回数
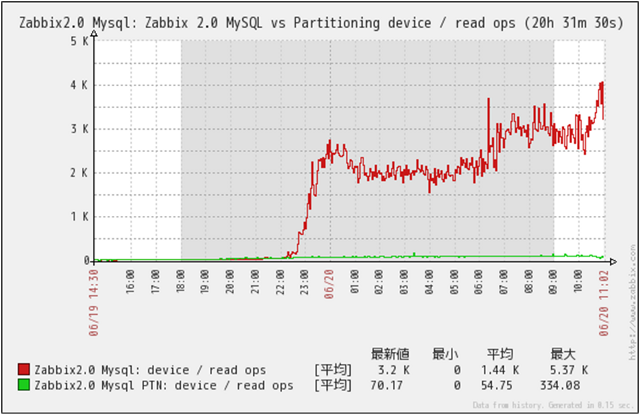
クリックで拡大
Disk Read回数の推移です。
MySQL(Non Partition)の場合、データ量増加に伴い限界を超えた所から、Read回数が急激に多くなっている事が判ります。
母体データ量が多くなり、メモリで処理できる限界値を超えた事によりDisk Readが多くなったものと推測できます。
MySQL_PTN(Partitioned)の場合、格納データ件数増加に伴うRead回数の上昇はほとんど見られません。
アクセス対象の母体データ量がPartition化により抑えられた事により、メモリ内で処理できているため、Read回数の急激な上昇が発生しなかったと推測できます。
Disk Write回数
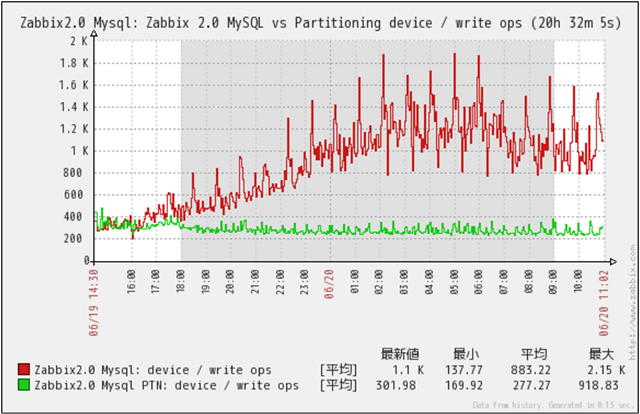
クリックで拡大
Disk Write回数の推移です。
MySQL(Non Partition)の場合、history関連テーブルのデータ量増加に伴いWrite回数が徐々に増えている事が判ります。
一定時間での収集するデータ量自体は増加していませんので、データ量増加によりSort等の処理がメモリ内で処理できる限界を超えた事によりI/Oが発生したものと推測できます。
MySQL_PTN(Partitioned)の場合は、一定のWrite回数で安定して動作している事が判ります。
今回は、収集データ量およびWebからのアクセスによる負荷をかけていますので、Read回数ほどの差は、出ていません。
Composite Partition検証
Composite Partitioningの検証では、データを多量に格納しないと差が見えてこない事が予想されるため、Composite Partitionとの比較で検証します。グラフの表示項目ですが、MySQL PTN RANGEは、ClockをPartition keyとしたComposite Partition構成です。MySQL PTN COMPは、ClockをPartition key 、itemidをSub Partition KeyにしてPartition化した構成です。
history関連テーブルの件数推移
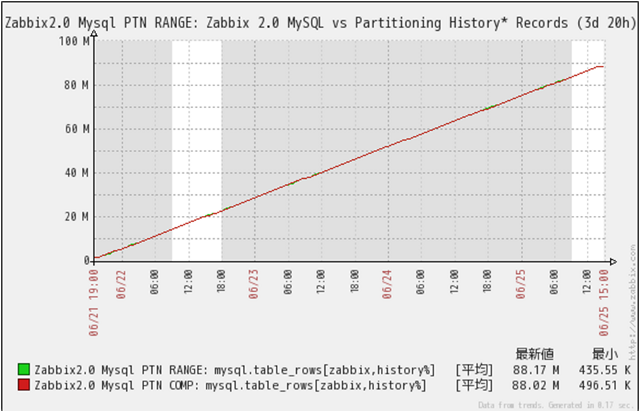
クリックで拡大
一番データ量が増えるhistory関連テーブルの件数推移です。
MySQL PTN RANGE、MySQL PTN COMP共に格納データが直線的に増加しており格納件数の伸びが落ち込んでいない事が判ります。
CPU Idleの推移
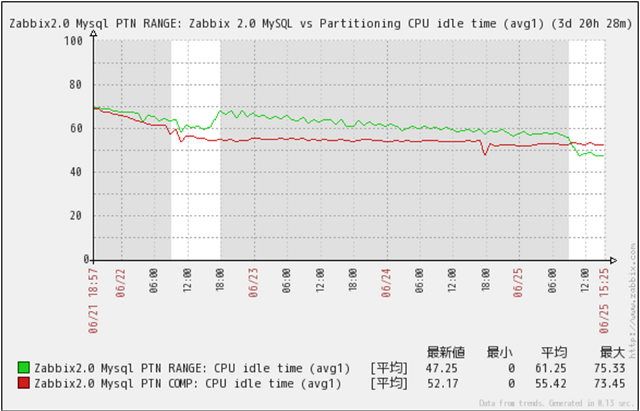
クリックで拡大
CPU Idleの推移です。
MySQL PTN RANGE、MySQL PTN COMP共に、格納データ件数増加に伴いCPU Idleが減少しているのですが、データ件数が9千万件を超えても十分な余力がある事が判ります。
Disk Read回数
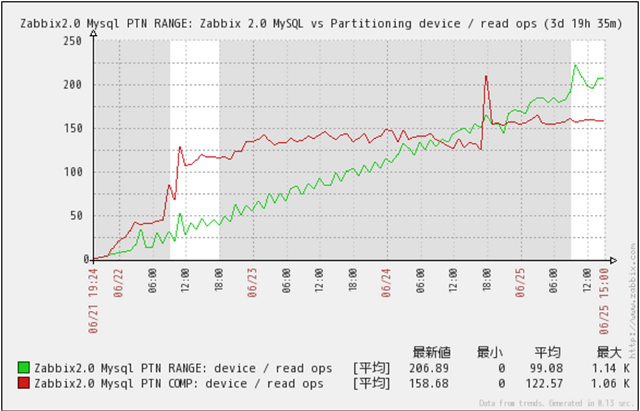
クリックで拡大
Disk Read回数の推移です。
MySQL PTN RANGEは、データ件数増加に伴い少しずつRead回数が上昇している事が判ります。
絶対値が少ないのと、格納データ件数が、非常に多いので実際の環境では、ほとんど影響が無いと推測できます。
MySQL PTN COMPに、データ件数が増加しても、ほぼ一定の状態です。
ただし、MySQL PTN COMPの方が、初期のOverheadが大きい事が見て取れます。
Disk Write回数
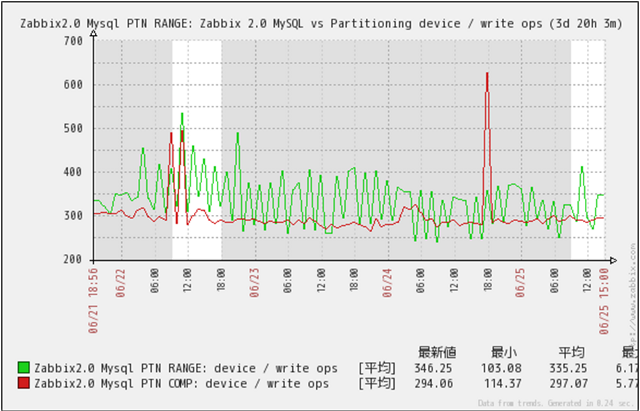
クリックで拡大
Disk Write回数の推移です。
MySQL PTN RANGE、MySQL PTN COMP共に、一定のWrite回数で安定して動作している事が判ります。
MySQL PTN RANGEの方が若干高めですが、実際の環境では、ほとんど影響が無いと推測できます。
結果
Range Partition , Hash Partition, Composite Partition共に、1千万件以上にデータ件数が増加してもCPU使用率、I/O使用率が少なく、非常に安定して動作する事が確認出来ました。
検証した其々のPartitionは、分割の仕組みが異なるため、データ件数の増加に対して各リソースの使用率が変わる事を予想してたのですが結果として、ほぼ同じリソースの使用状態になる事が判りました。
Range Partition と Composite Partitionの比較では、約9千万レコードまでデータを格納して検証したのですが、ほぼ同じリソースの使用率となりました。
8千万レコードを超えたあたりから若干Composite Partitionの効果が出てきているようですが、収集するITEM数を非常に多い条件にしないと差が出ないと推測できます。
通常のPartitioningを使用しないMySQL(Non Partition)で、CPUを使用率が上がる主な理由は、データ件数増加に伴うDisk Read/Write回数の増加が大きな要因と推測できます。
Zabbixが発行しているSQL自体は、ほぼ同じなので、Web(PHP)およびMySQLがメモリ内で処理できる限界を超えたため、および格納先ファイルサイズが大きくなったためにRead/Write回数が増加したものと推測できます。